
2019年3月7・8日に、サイバーセキュリティシンポジウム道後2019(SEC道後2019)に参加してきました(イベントサイトはこちら:http://www.sec-dogo.jp/)。
今回は、前回のレポート(サイバーセキュリティシンポジウム道後2019 イベント参加報告 Part 1「えーあい・みーつ・せきゅりてぃ 前編」)に引き続き、「えーあい・みーつ・せきゅりてぃ」の後編(質疑応答)をレポートしたいと思います。その他の講演については、イベントサイトの以下のリンクよりダイジェストを読むことが出来ます。
http://www.sec-dogo.jp/digest/
本ブログをご覧になった方の中で、間違いや不正確な内容があったらご指摘いただけると幸いです。

「えーあい・みーつ・せきゅりてぃ」
講演者:申 吉浩 先生(兵庫県立大学、Carnegie MellonUniversity)山川 宏 先生(NPO 法人全脳アーキテクチャ・イニシアティブ、ドワンゴ人工知能研究所研究所長、https://www.facebook.com/hiro3ymkw)
7質疑応答
Q1:機械学習は汎用型人工知能(AGI)のバックボーンだと言ったが、汎用型人工知能ならではの分野とかシステムを作るうえで構築しなければいけないことは何か?
A1(山川 宏):
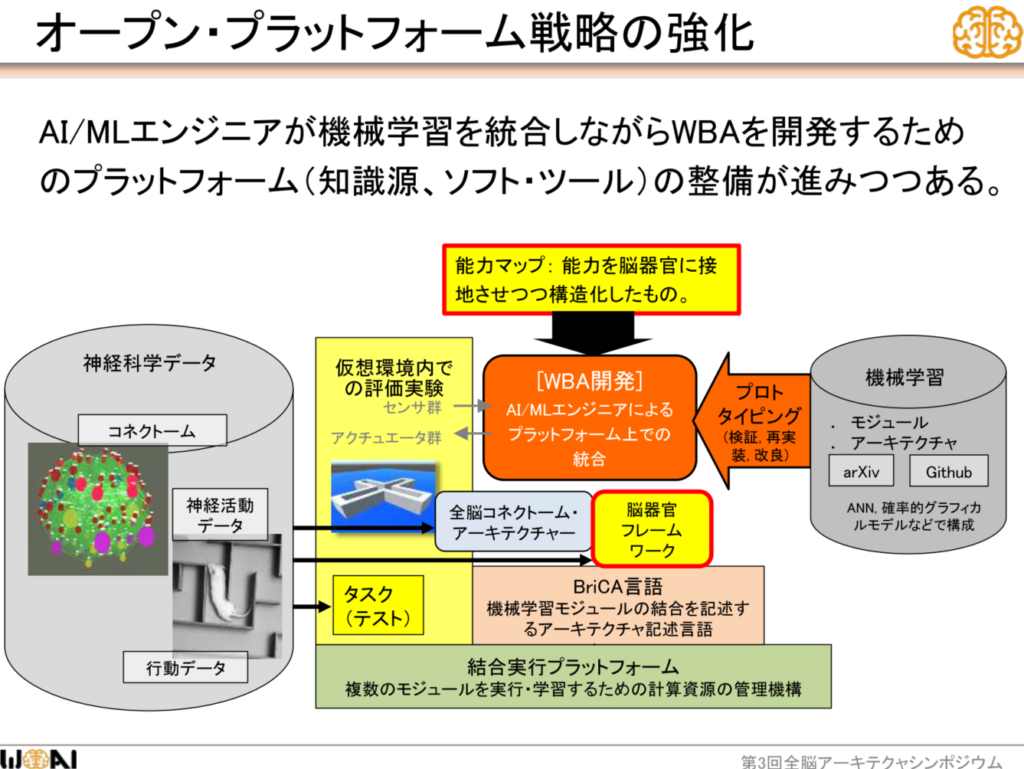
以下の画像の②アーキテクチャ開発、③モジュールの組み合わせを操作する仕組み、がそれにあたる。
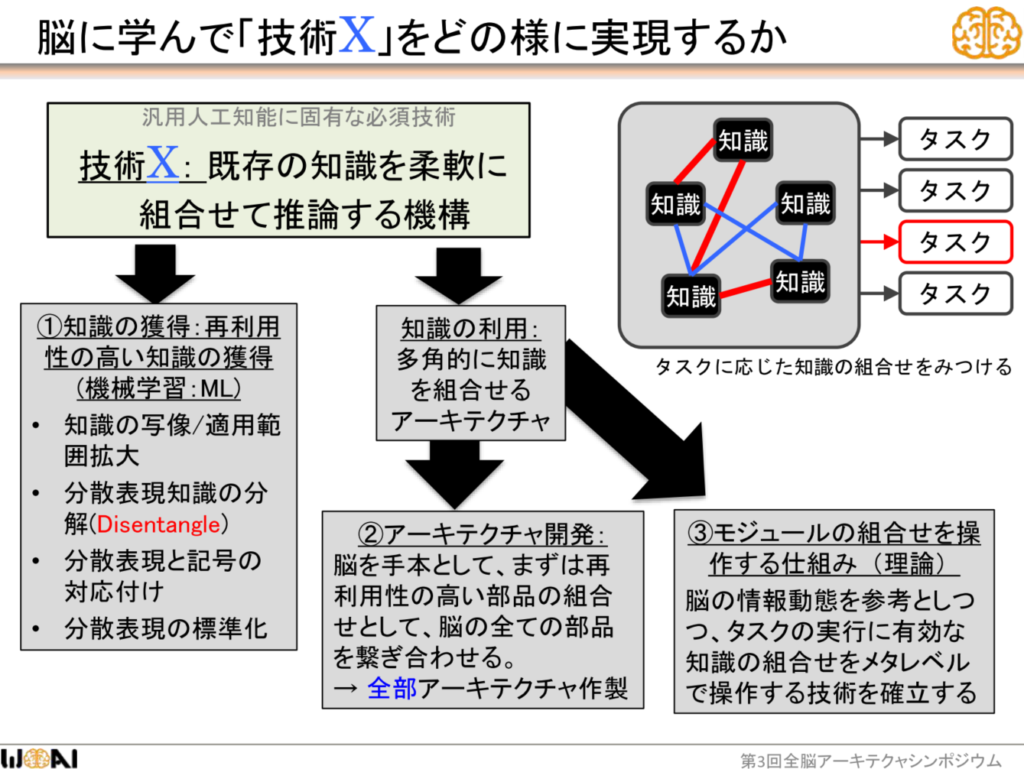
「https://www.slideshare.net/wba-initiative/agi-105454822」より引用
「アーキテクチャ開発」とは、前頭葉、後頭葉、側頭葉、脳幹、小脳などの脳器官の仕組みや役割、そして脳器官同士のコミュニケーションを参考にしたアーキテクチャやフレームワークを設計・開発することである。また、そのような思想に従ってシステムエンジニアが開発をしやすくするためのプラットフォームの作成も行っている。このフェーズでは、各脳器官の機能を再現し、「とりあえず各脳器官の仕組みを再現する部品は全て揃える」状態にすることに重点が置かれる。
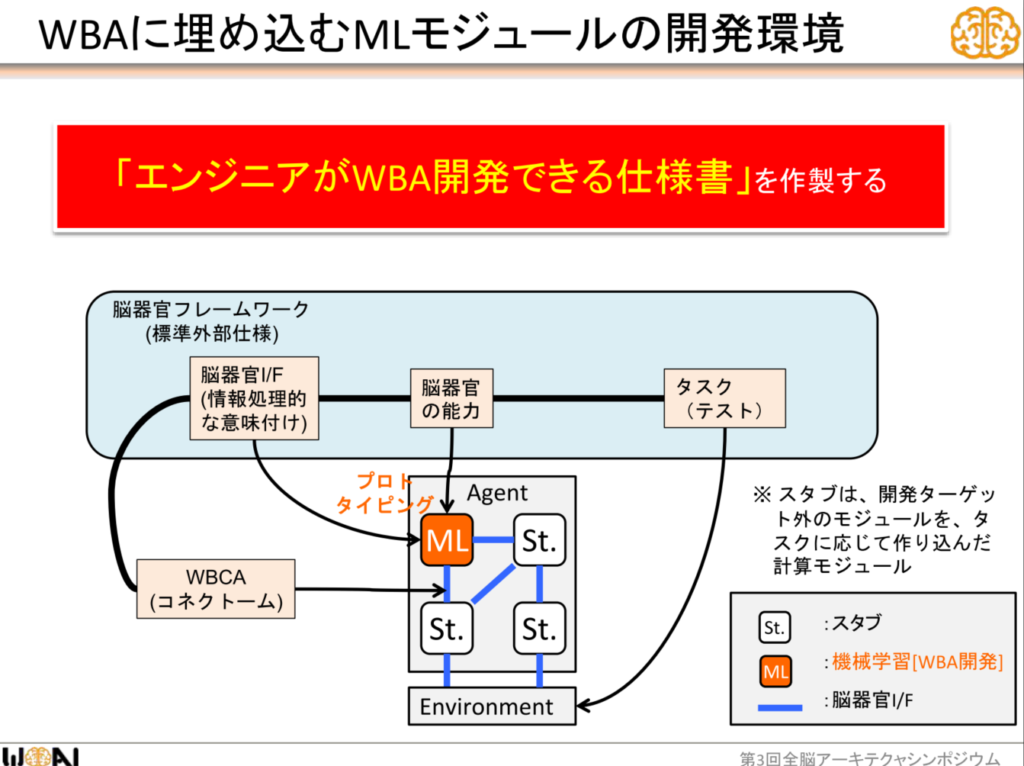
「https://www.slideshare.net/wba-initiative/agi-105454822」より引用
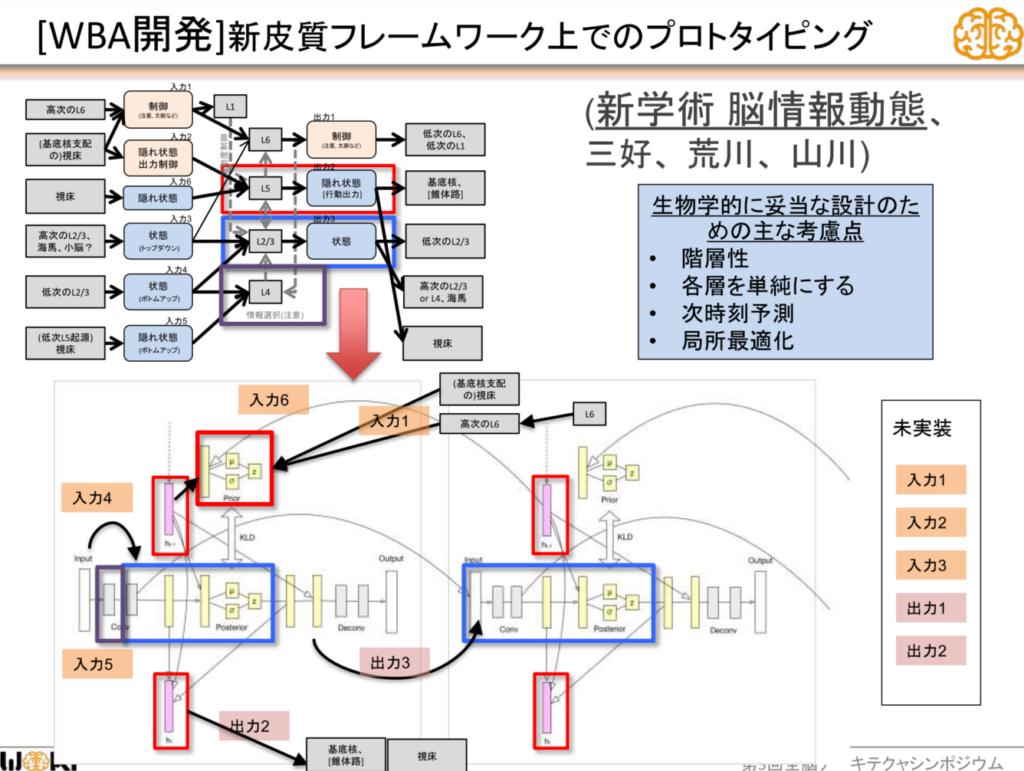
「https://www.slideshare.net/wba-initiative/agi-105454822」より引用
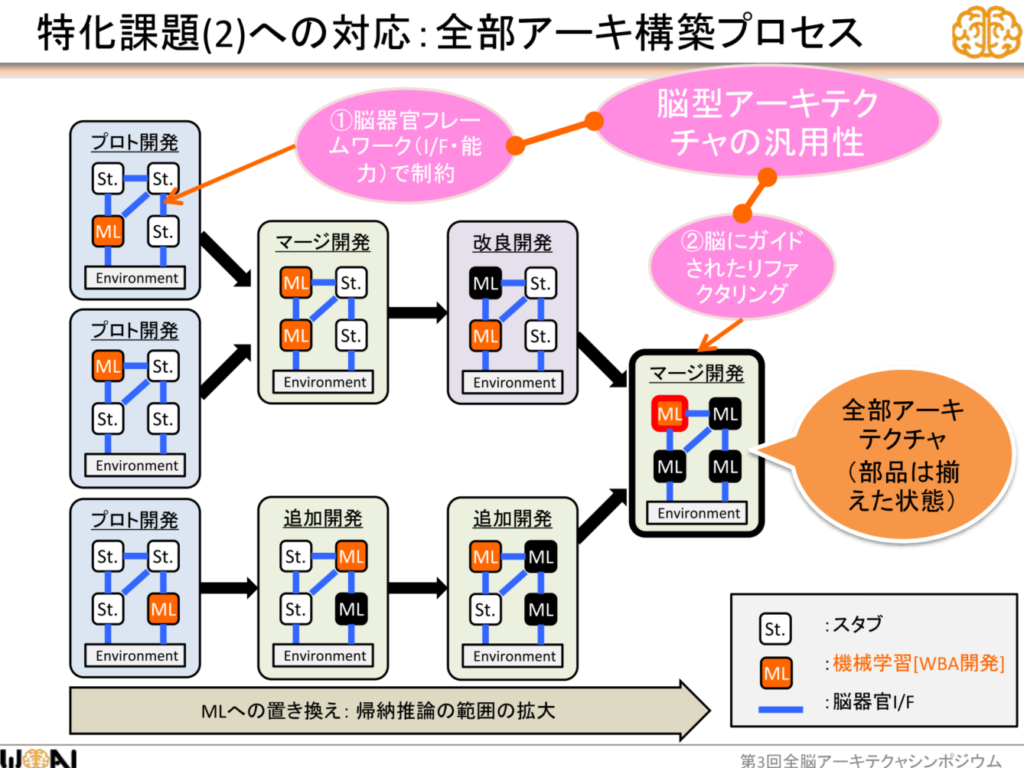
「https://www.slideshare.net/wba-initiative/agi-105454822」より引用
「https://www.slideshare.net/wba-initiative/agi-105454822」より引用
「モジュールの組み合わせを操作する仕組み」とは、「アーキテクチャ開発」で揃えた各脳器官に対応する部品を結合する取り組みのことである。下記の図の左から右に移行することを意味する。
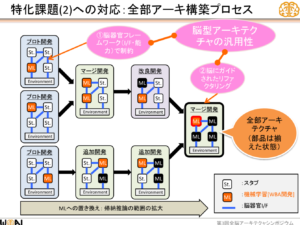
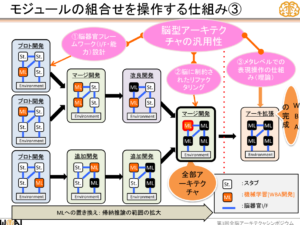
Q2:汎用AIを作る上での課題・難しいところは何か?
A2(山川 宏):
「常識」がない事(常識というものを明文化し実装しないといけないこと)。フレーム問題(どこまでの知識や情報を、注目している事象と関連付けて考えるべきか決める事。参考URL:https://www.nicogame.info/ja/watch/sm33107484 (3:50から)、https://www.youtube.com/watch?v=RdsG7dFloF0&t=371s)。
特化型AIであれば実現できる理由は、取り組むべきタスクを限定しているのでフレーム問題が顕在化しないから。
Q3:前例のない(=学習データのない)意味不明なデータやパケットの加工をして、脅威インテリジェンスを使って、その加工によりアンチウイルスソフトを抜けるかどうかチェックすることが現実では可能なので、機械学習搭載のセキュリティでもあまり意味がないのでは?
A3(申 吉浩):
原理的には防げるが、現実問題では回避するには多大なコストがかかるので、その費用対効果をどう考えるかだと思う。例えば、フィッシングサイトと正規のサイトを見極めることを考える。申先生のラボの実験では99%以上分類できた。しかし、依って立つものはフィッシングサイトの寿命が短い事。そして、クラッカー側が採算をとるために同じようなデザインのサイトを沢山作ること。そういう前提に基づくと、AIを使ったセキュリティシステムにも意味が出てくる。また、データの特徴量の選定においても、特化型AIだと人間にも思いつかないような切り口でデータの解釈を見つけられるので、たとえ検知システムに搭載しない売でも、機械学習をセキュリティ分野で利用することには大きな意味がある。
Q4:AIが攻撃者になったらどうなる?
A4(申 吉浩):
人間対人間の攻防で起こっているイタチごっこと同じような問題が起こると思う。人間対人間で言うところのゼロデイ問題のようなことも起こるかもしれない。攻撃者が特化型AIだと、監視する対象のパケットが決まっているのでそこを防御すれば良い。しかし、汎用型AIが攻撃する場合、どこを攻撃してくるのかわからないため防御が非常に難しくなる。
Q5:量子コンピュータと量子暗号がセキュリティと機械学習にに与える影響は?RSA暗号は役に立たなくなるのか?
A5(申 吉浩):
今の暗号は現在主流のパソコンのアーキテクチャ(=チューリングマシン)が持つ計算能力を前提とした計算量的安全を担保している。しかし、量子コンピュータは、問題の複雑性(サイズ)が増すにしたがって、チューリングマシンの数百・数千倍以上のオーダーで処理速度を上げることができる。
RSA暗号がベースとしている素因数分解問題(正確には、RSA暗号は素因数分解問題より解くのが簡単なRSA問題をベースとしている)は、量子コンピュータを用いて多項式時間で解くアルゴリズム(Shorのアルゴリズム)が知られているため、RSA暗号は多項式時間で破ることが可能となり、安全でなくなる。
離散対数問題も素因数分解問題と本質的に同じ困難性を有するため、同じ運命をたどることになる。楕円曲線における離散対数問題は、現状、Pohlig-Hellmanアルゴリズムが最も効率的なアルゴリズムとして知られているが、これも量子コンピュータにより次元の異なる高速化が可能となると考えられているため、安全性に問題が出るものと予想されている。
素因数分解問題も離散対数問題も、NP完全問題ではないと信じられているので、量子コンピュータが実用化されると安全性に影響が出ると思われるが、だからと言って、対抗手段がないわけではない。ナップザック暗号と量子暗号がその手段だ。ナップザック暗号は、RSAが発表されたのと同時期(1977-1978年)に作られた公開鍵暗号の一つで(Merkle-Hellmanナップサック暗号、暗号技術入門 第3版 秘密の国のアリス P119)、NP完全問題の困難性に安全性の根拠を置いている。これまでに発表されたナップザック暗号の多くは破られており(格子理論を用いる)安全でないことが証明されているが、それ以外の方式については、安全性の証明(暗号の安全性がナップザック問題に帰着されることの証明)が存在しない。余談になるが、発表されたナップザック暗号が破られた原因は、秘密鍵の一部に「超増加数列」を用いていることが脆弱性の原因になっているためである。つまり、ナップザック暗号の解読は決して簡単だった訳ではなく、高度な格子理論により発見された解読法ならば「効率的に解読」が可能であるというのが正確な表現である。
量子暗号の研究も盛んである。実を言うと、量子暗号(正確には量子理論に基づく鍵交換プロトコル)はすでに実用化されている。BennetとBrassardにより1984年に発表されたBB84というプロトコルがそれにあたり、第三者が盗聴しようとすると内容が変化し、さらに盗聴されたことが必ず判明するという特性を持つ。しかし、この鍵交換方式は量子コンピュータを前提としていない。現在では、量子コンピュータを用いた暗号方式が深く研究されている。
上記二つの暗号技術が、量子コンピュータよりも早く実用化されると考えるため、量子コンピュータによってネットワークセキュリティが破壊されるとは思わない。しかし、既存の暗号通信方法から、ナップザック暗号や量子暗号に乗り換えるには、相当なコストがかかるため、そこは別途議論しなければならない(逆に言えばそこにビジネスチャンスがあるかもしれない)。
NP完全問題については、以下を参照すると良い。
http://motojapan.hateblo.jp/entry/2017/11/15/082738
*補足:ナップザック暗号と超増加数列(super-incrementing series)について
ナップザック問題は、「数列a_1, …, a_nと S = b_1 * a_1 + … + b_n * a_n が与えられて、秘密のバイナリ数列 b_1, …, b_nを求めよ(b_i = 0 or 1)」という問題です。一般的には、ナップザック暗号はNP完全ですが、a_1, …, a_nの選び方によっては、多項式時間で解けます。例えば、超増加数列(super-increasing series)とは、a_n > a_1 + … + a_(n-1) が成り立つことをいい、典型的な例かつ最小の数列は、a_k = 2^(k-1) です。この a_k から計算された前述のSから、b_1, …, b_n を求めることは、与えられた数 S の二進表現を求めることに他ならないので、簡単に解ける問題になります。ナップザック暗号の多くの例では、復号ができないといけないので超増加数列を使うため、本質的にNP完全な問題に依拠していません。加えて、a_1, …, a_nを隠すために、色々な工夫をする必要があります。
Q6:日本でも機械学習を使ったセキュリティ製品を作れるか?
A6:
「日本では、機械学習の研究は盛んで世界でもトップレベルだが、データサイエンティストと呼ばれる人材の層は薄い。Googleが簡単に利用できる機械学習用のライブラリを大量につくってくれたので、機械学習を使ってR&Dをしたり開発をする機会に関しては、日本もアメリカも条件は同じである。違いがあるのは企業風土やベンチャースピリット。そして、日本企業は(セキュリティ製品の開発でなく、誰かが作った)セキュリティサービスを提供するビジネスをしたがる。その辺りが理由であまり日本初のセキュリティ製品が出てないのだと思う。」(申 吉浩)
「申先生も述べたような企業風土の差は大きいだろう。さらに、機械学習の適切な使い所を見極める能力を持つことはハードルが高いという課題がある。例えば、強化学習を使おうと考えた際、具体的に何の特徴量を強化学習で学ばせるのか、という所を設計するのが難しい。それから、機械学習を行うためのデータをちゃんと収集してるのか、というのもポイントで、少なくともデータを通じて問題を取り扱える準備が整っていることが必要である。」(山川 宏)



コメント